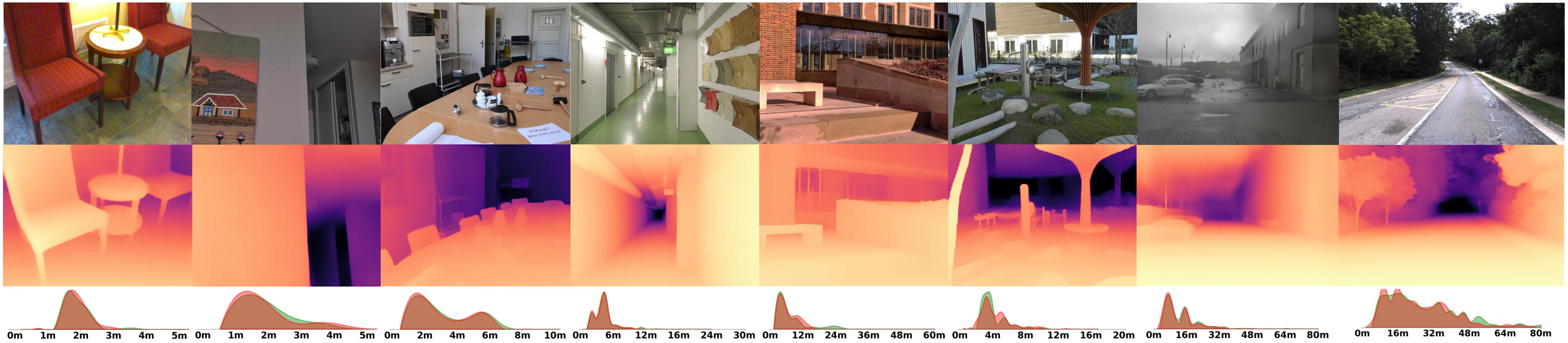
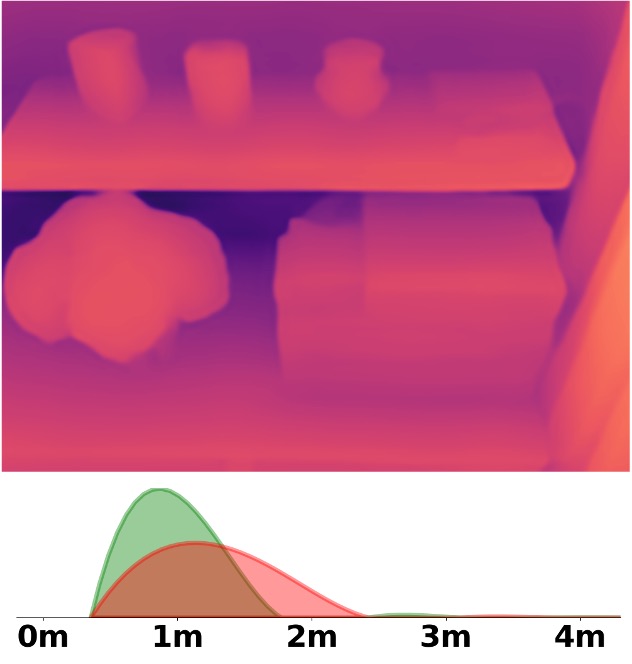
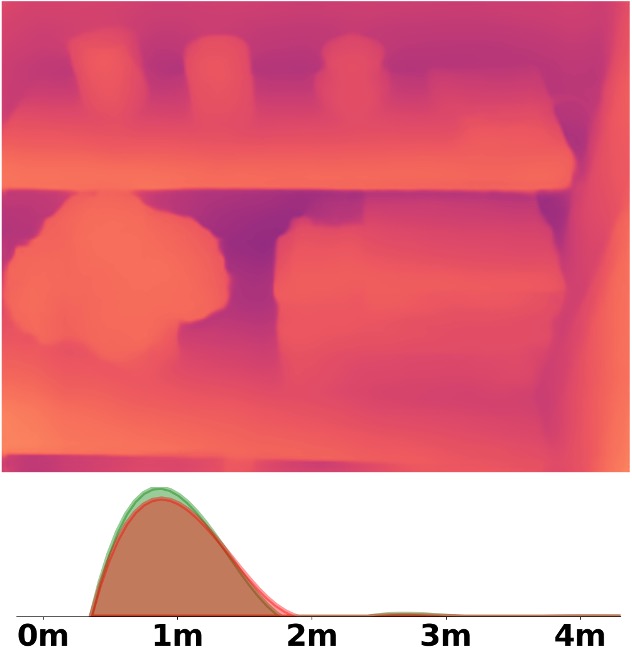
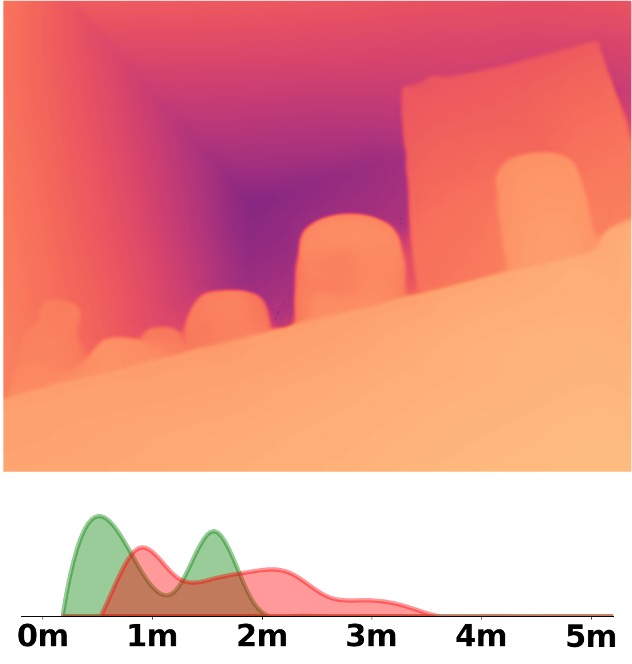
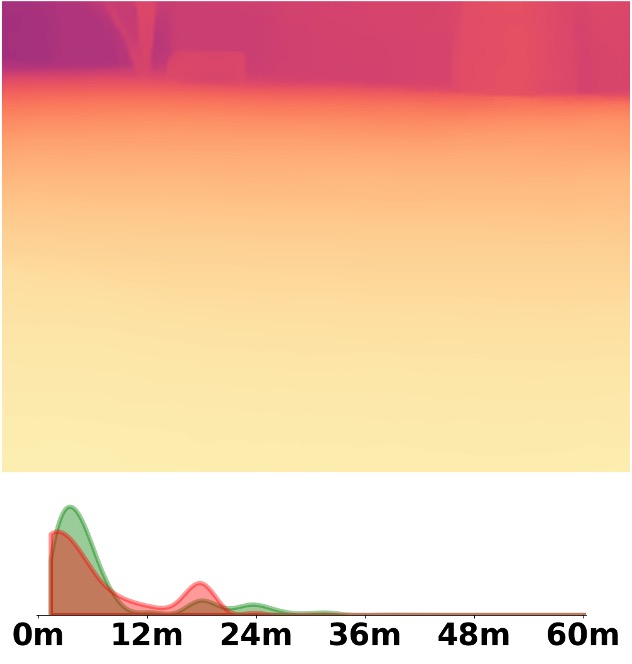
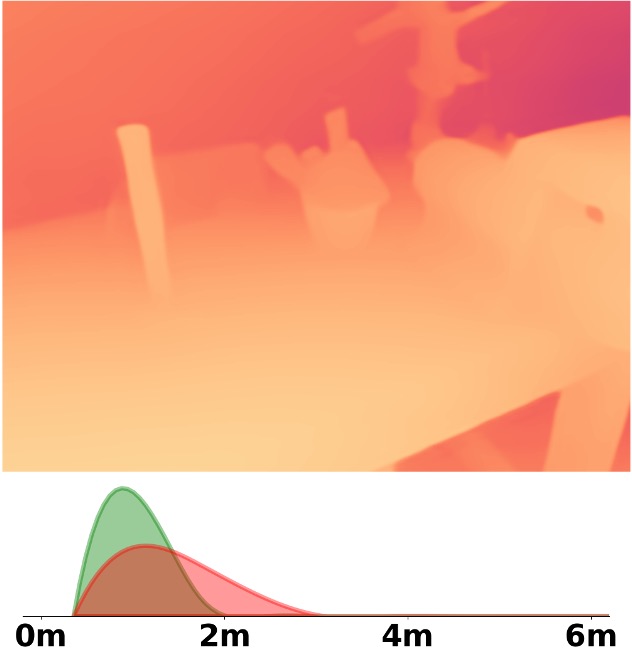
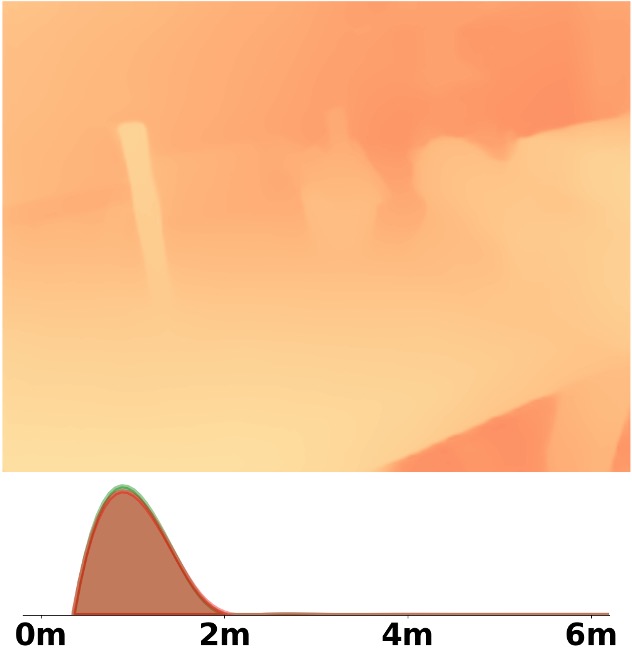
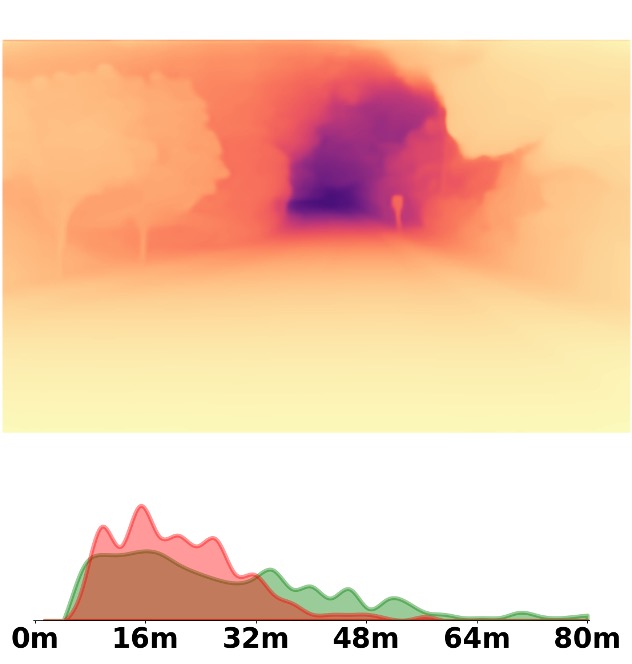
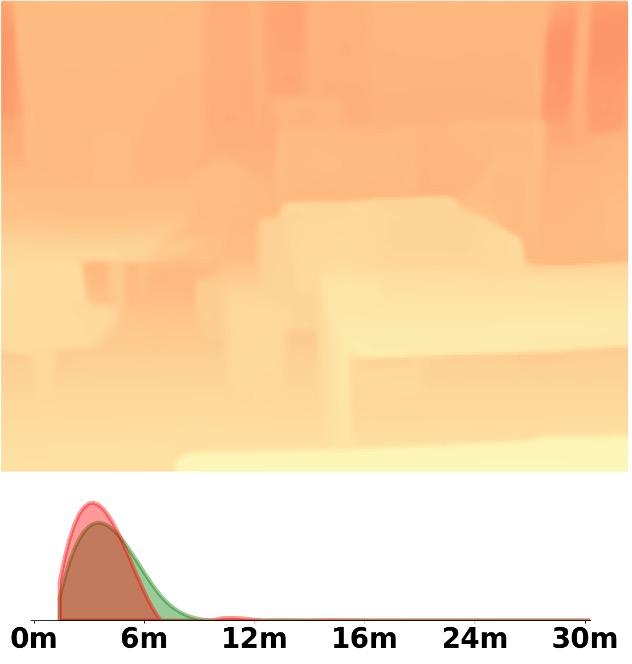
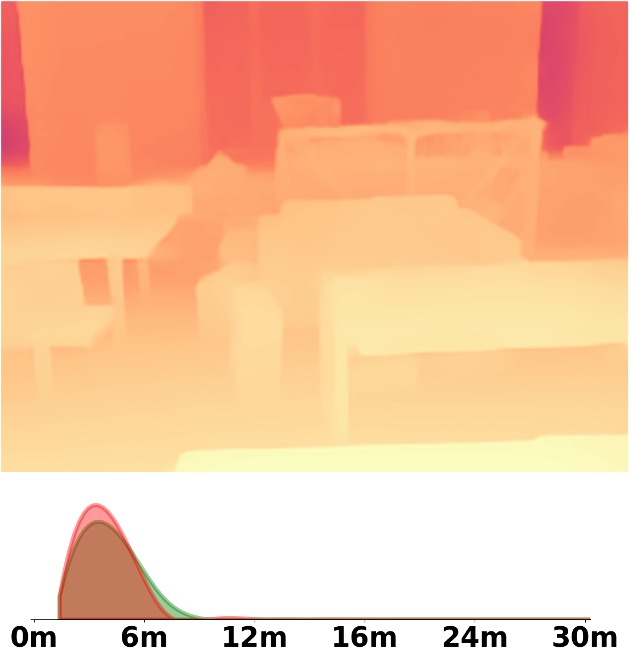
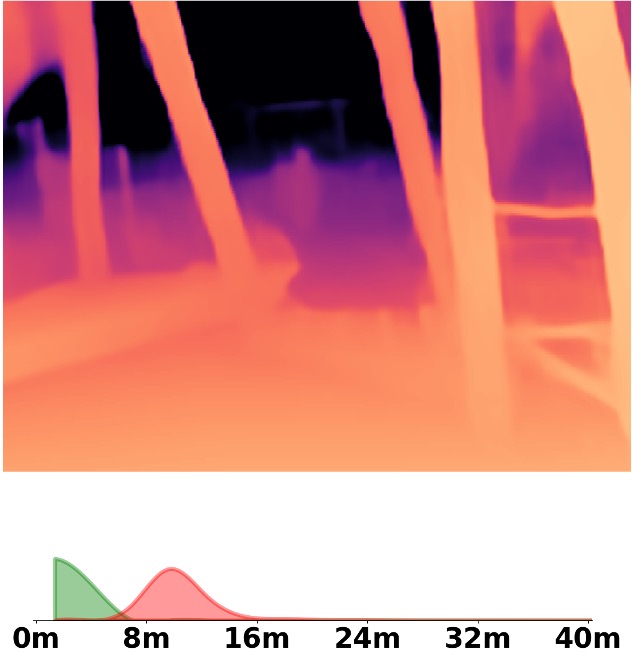
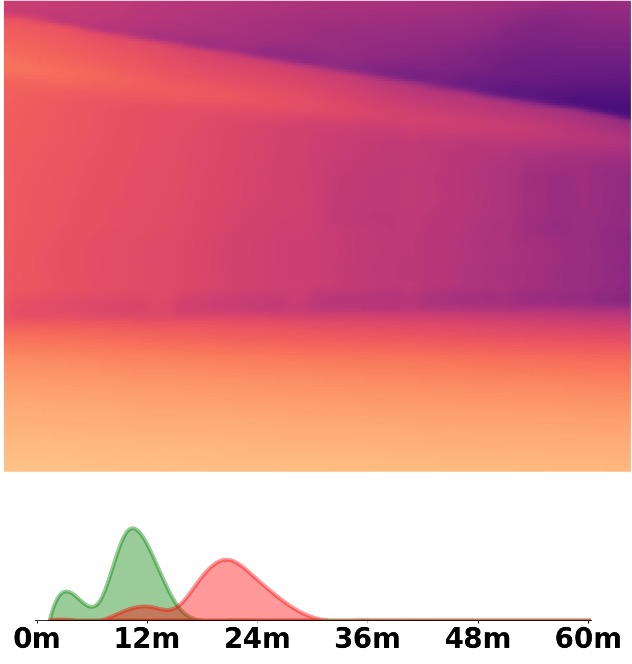
SM\(^4\)Depth is an approach to predict metric depth in never-seen-before scenes but is only
trained on 150K RGB-D pairs.
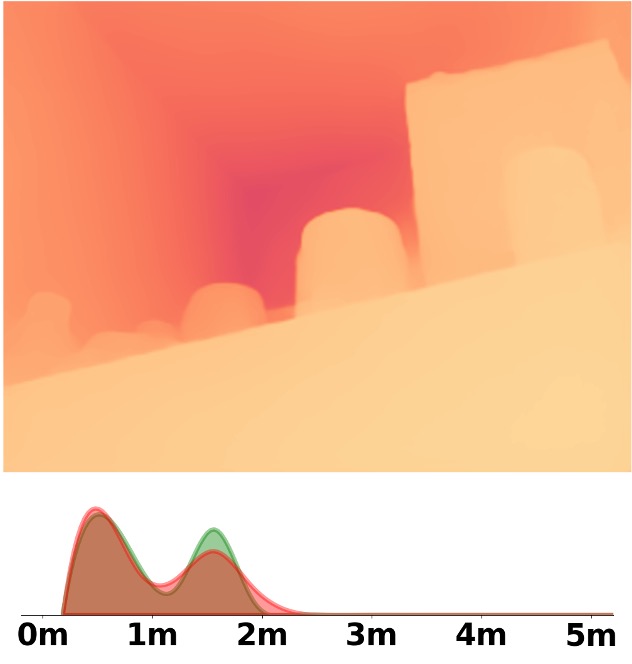
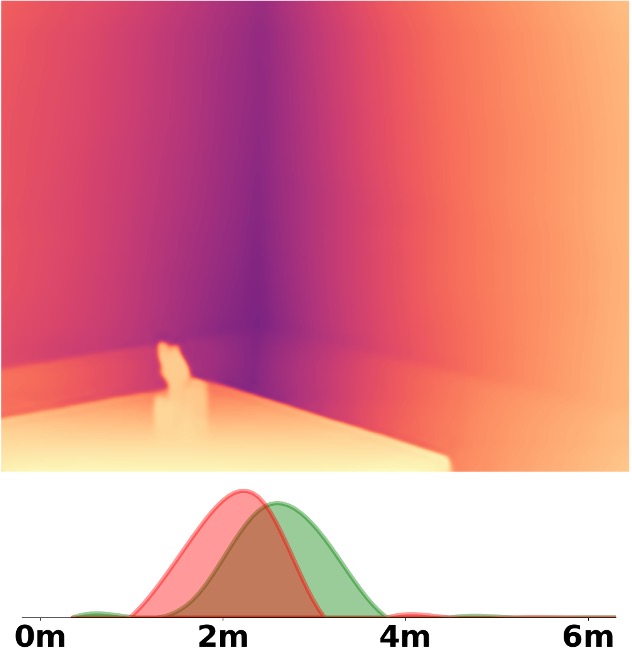
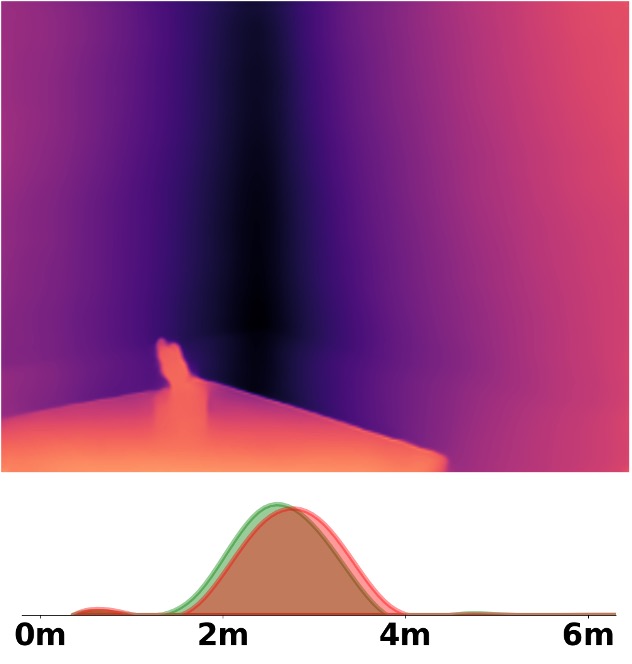
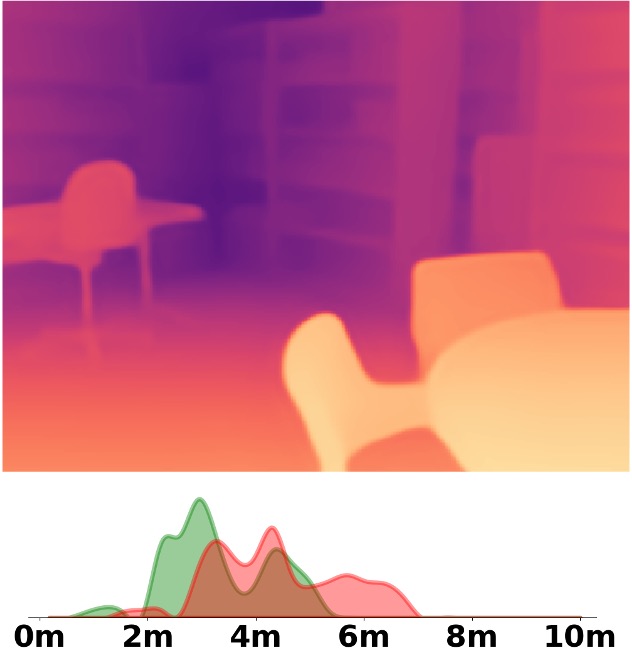
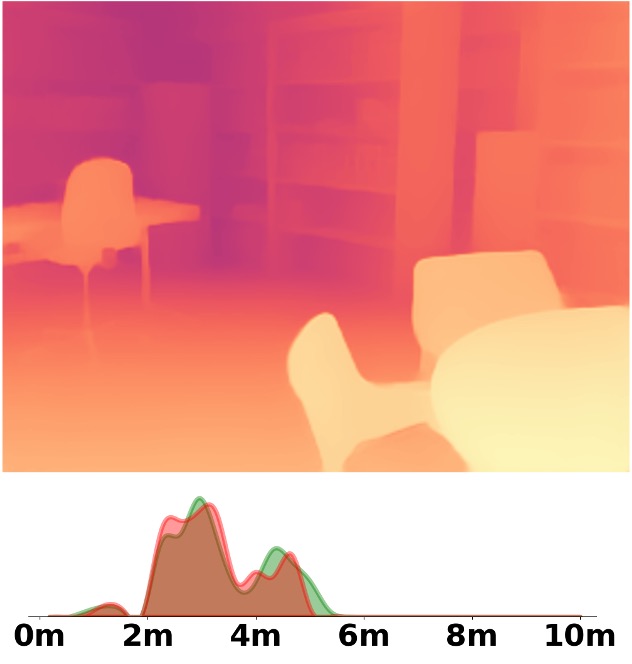
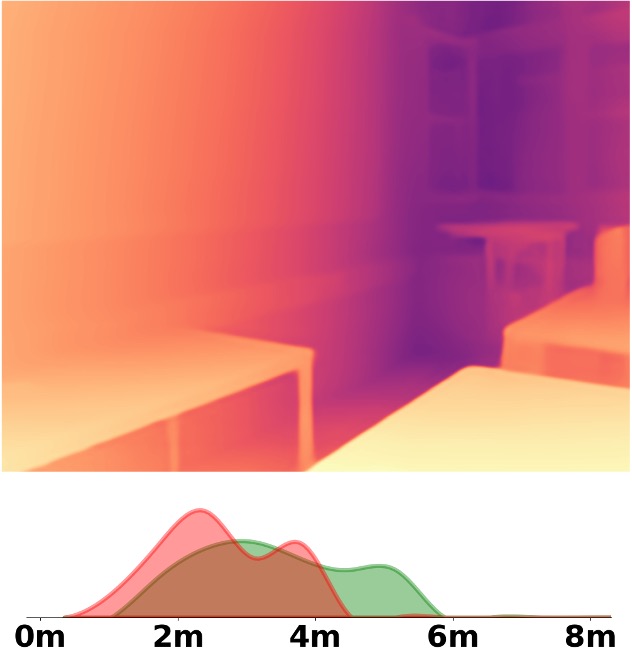
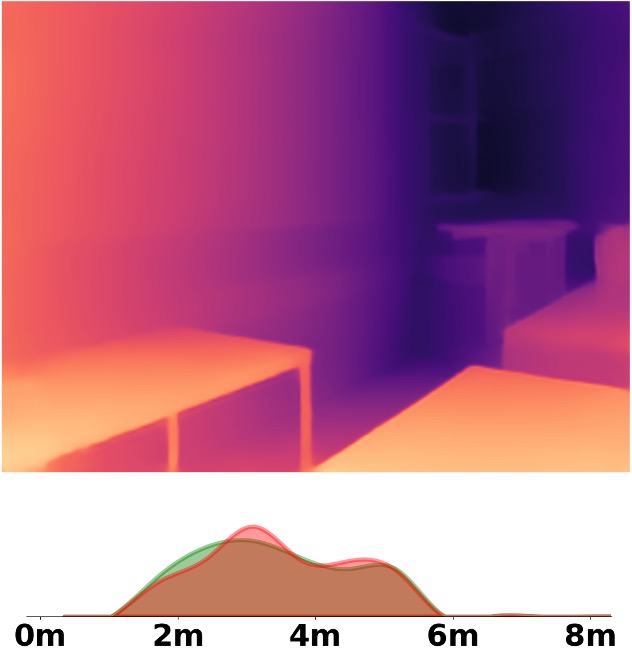
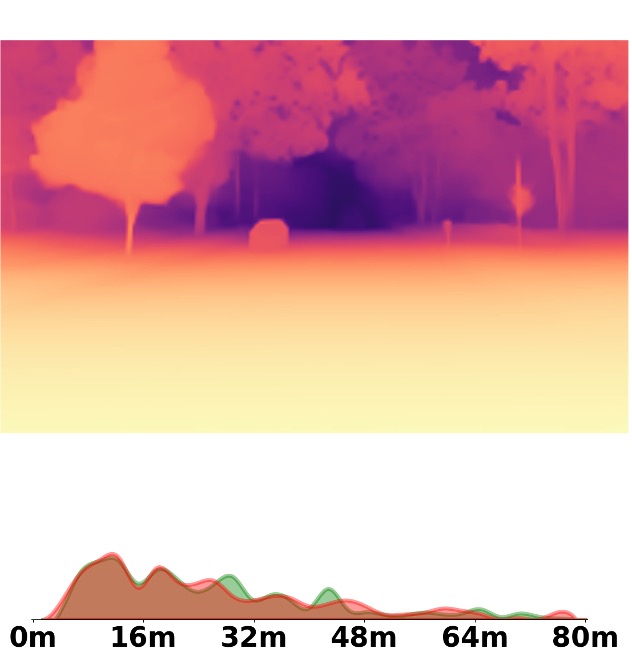
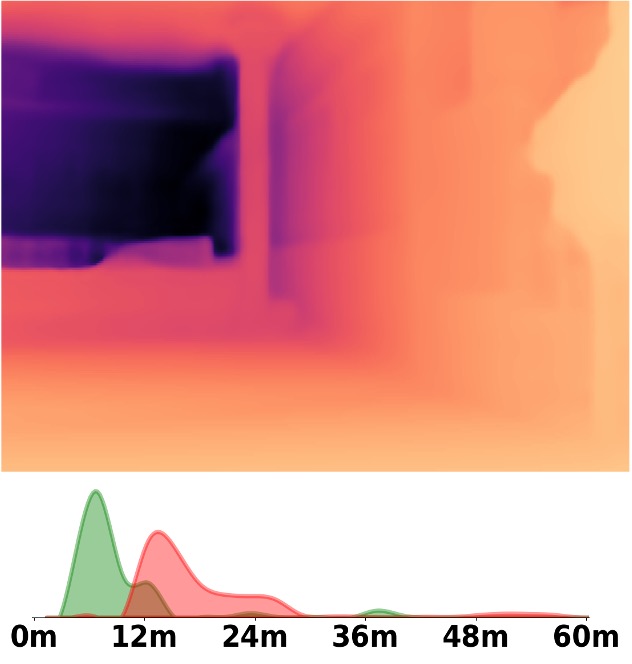
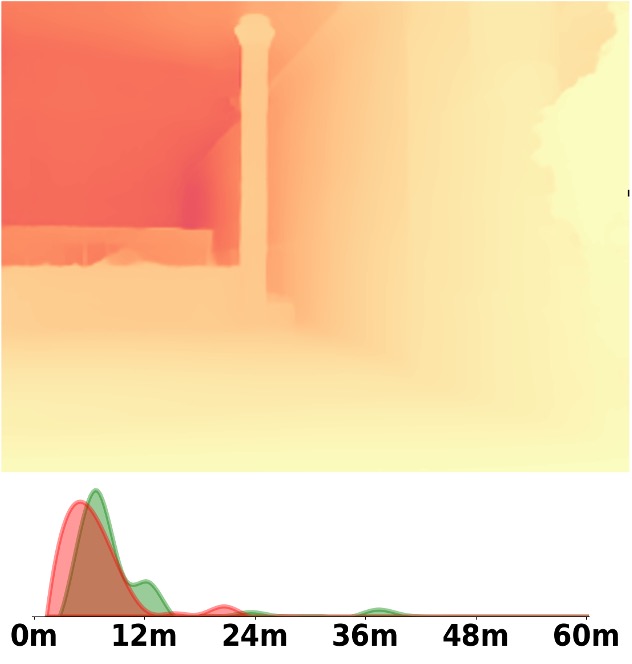
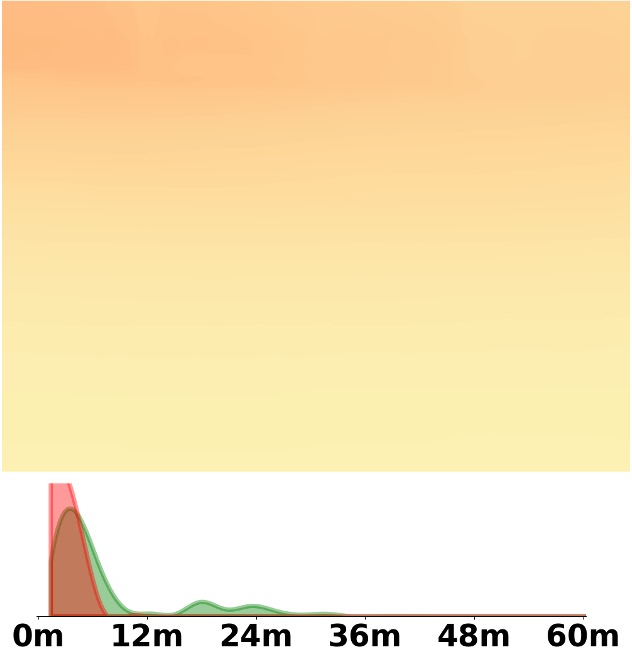
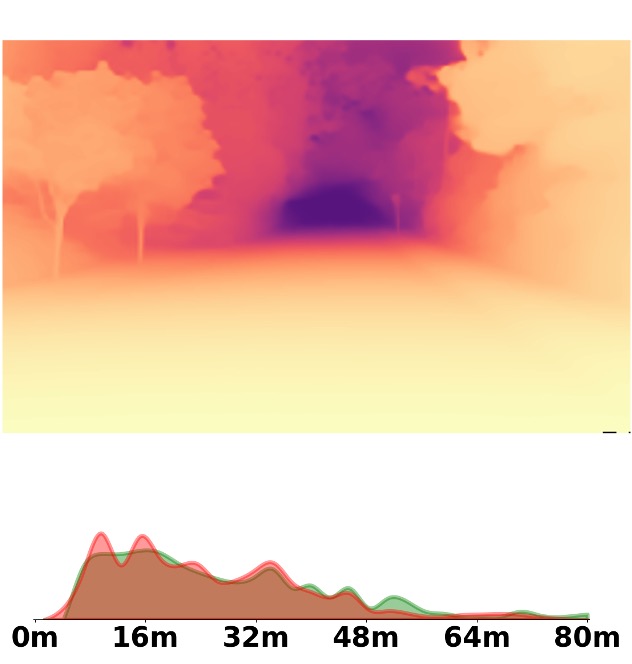
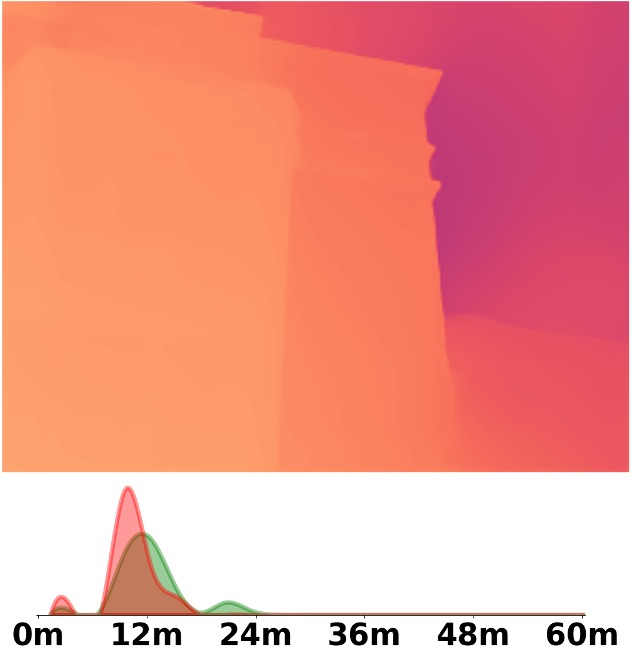
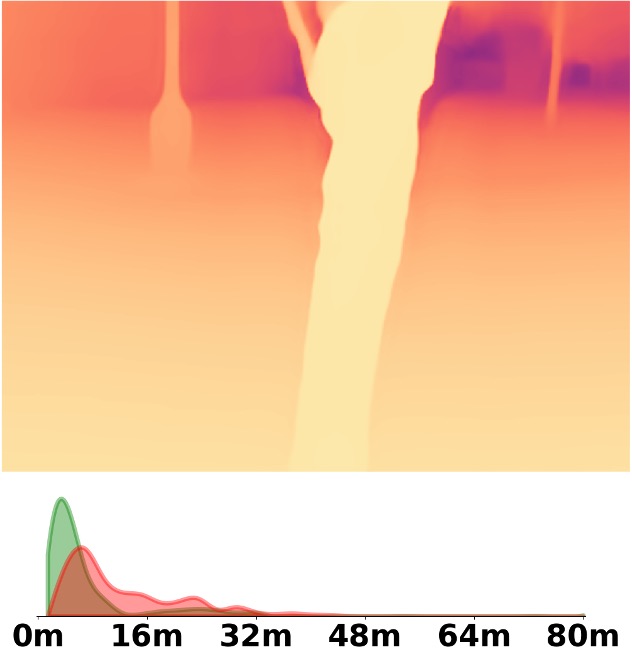
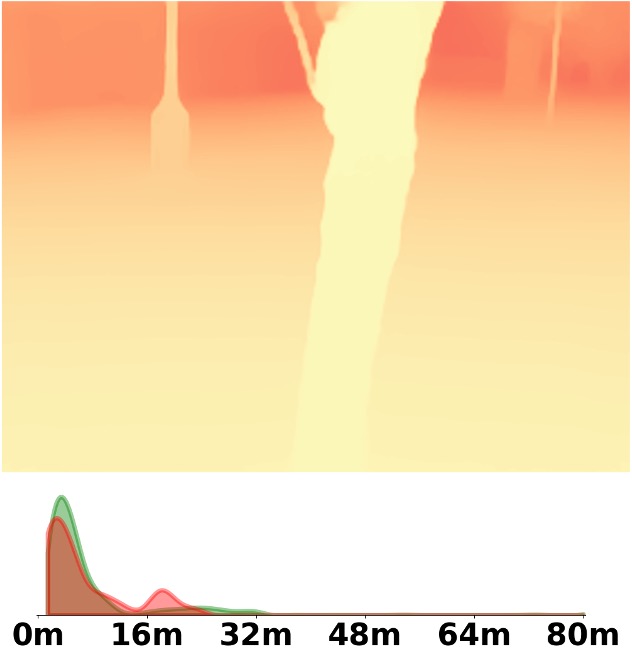
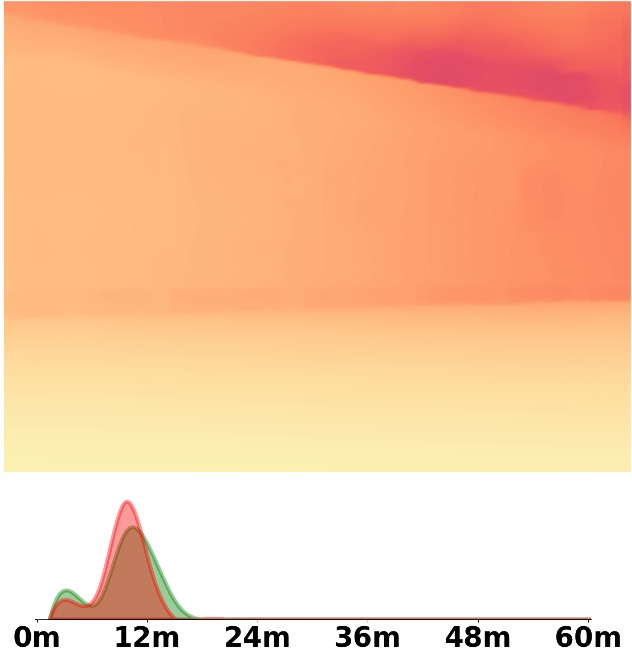
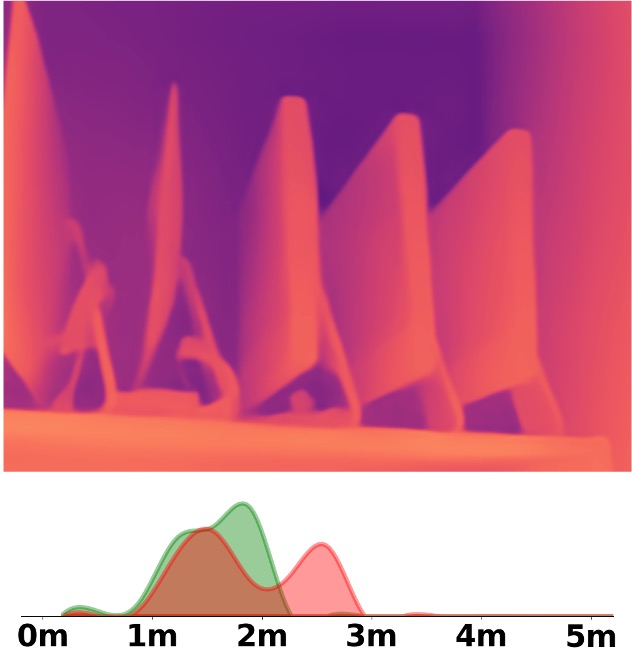
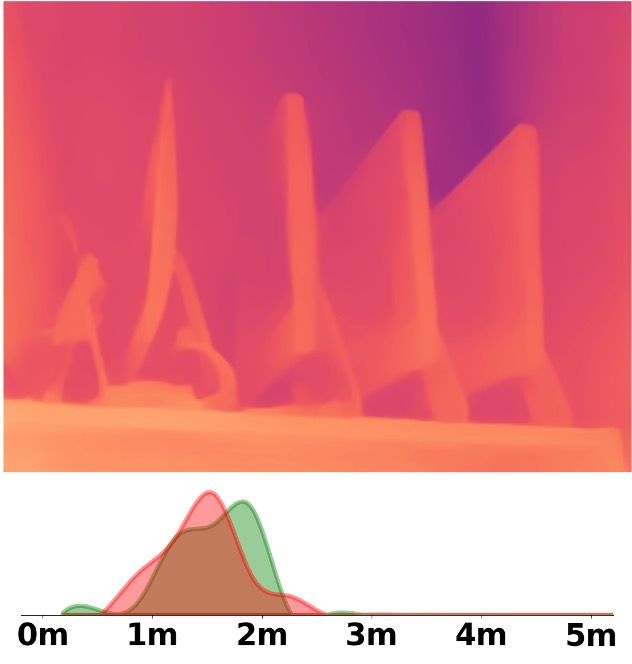
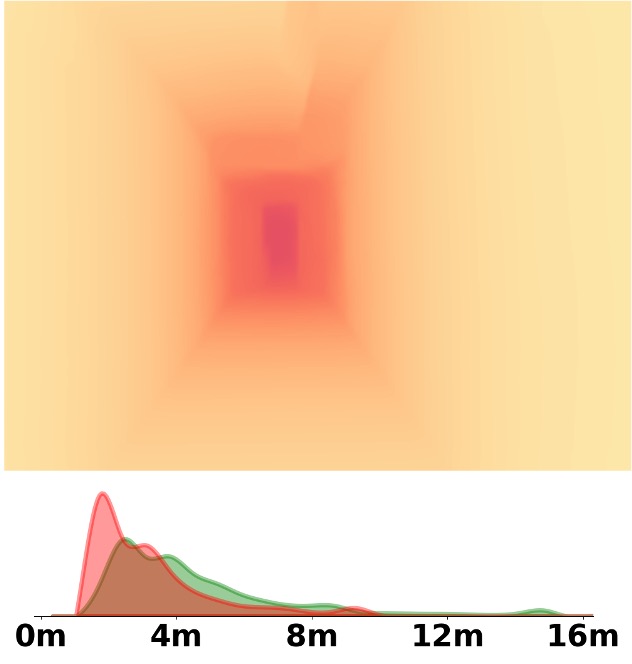
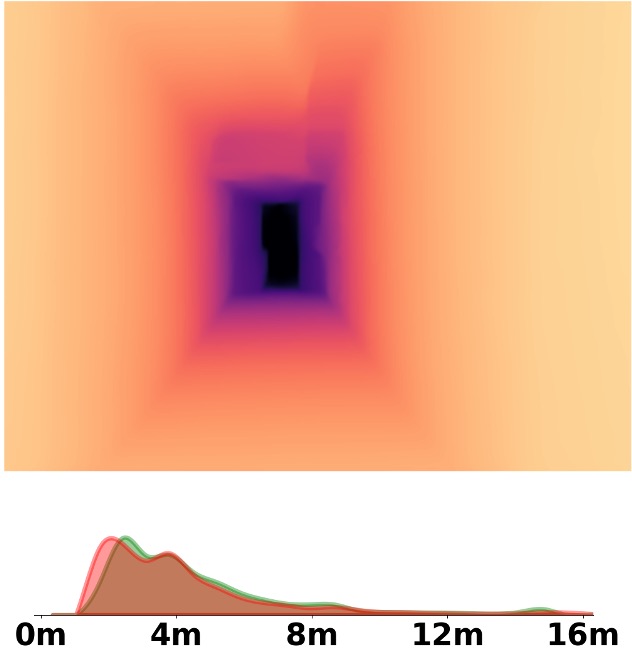
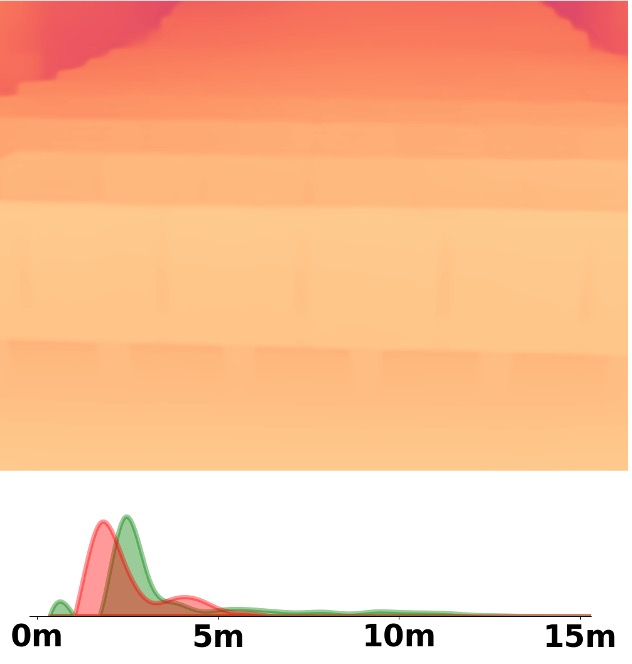
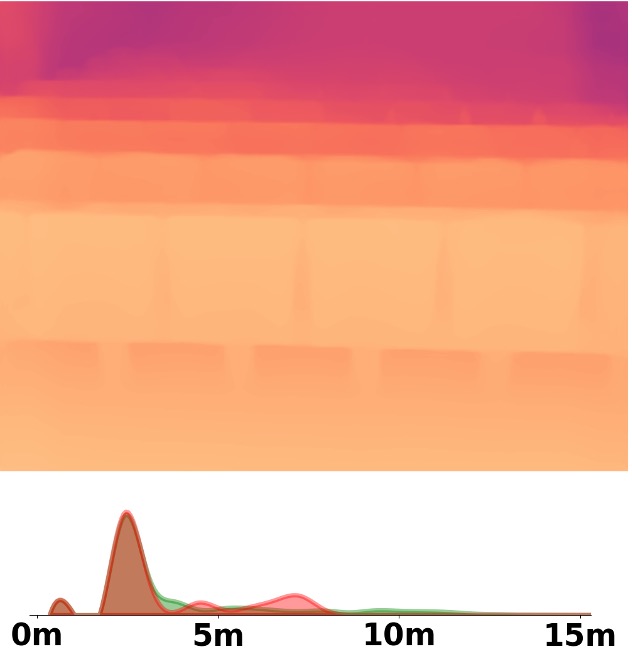
Visualization Comparison between SM\(^4\)Depth and ZoeDepth
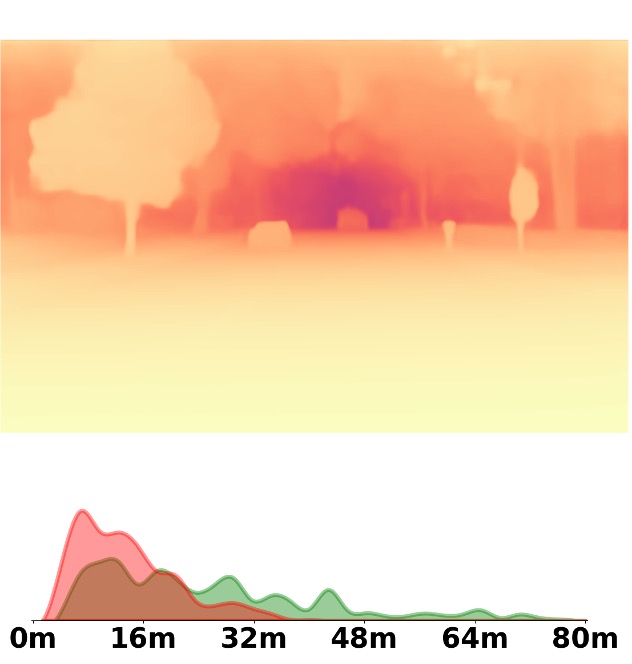
Depth and Distribution Visualizations on Real-world Videos
Note: The video was recorded by Huawei Mate40 (\(4K@30FPS\)), and the focal length is \(f_x=3278.24\),
\(f_y=3278.13\).
We employ the officially provided code of all methods in this comparison.
Due to the lack of ground truth depth, this qualitative comparison is for reference only.
Advantages
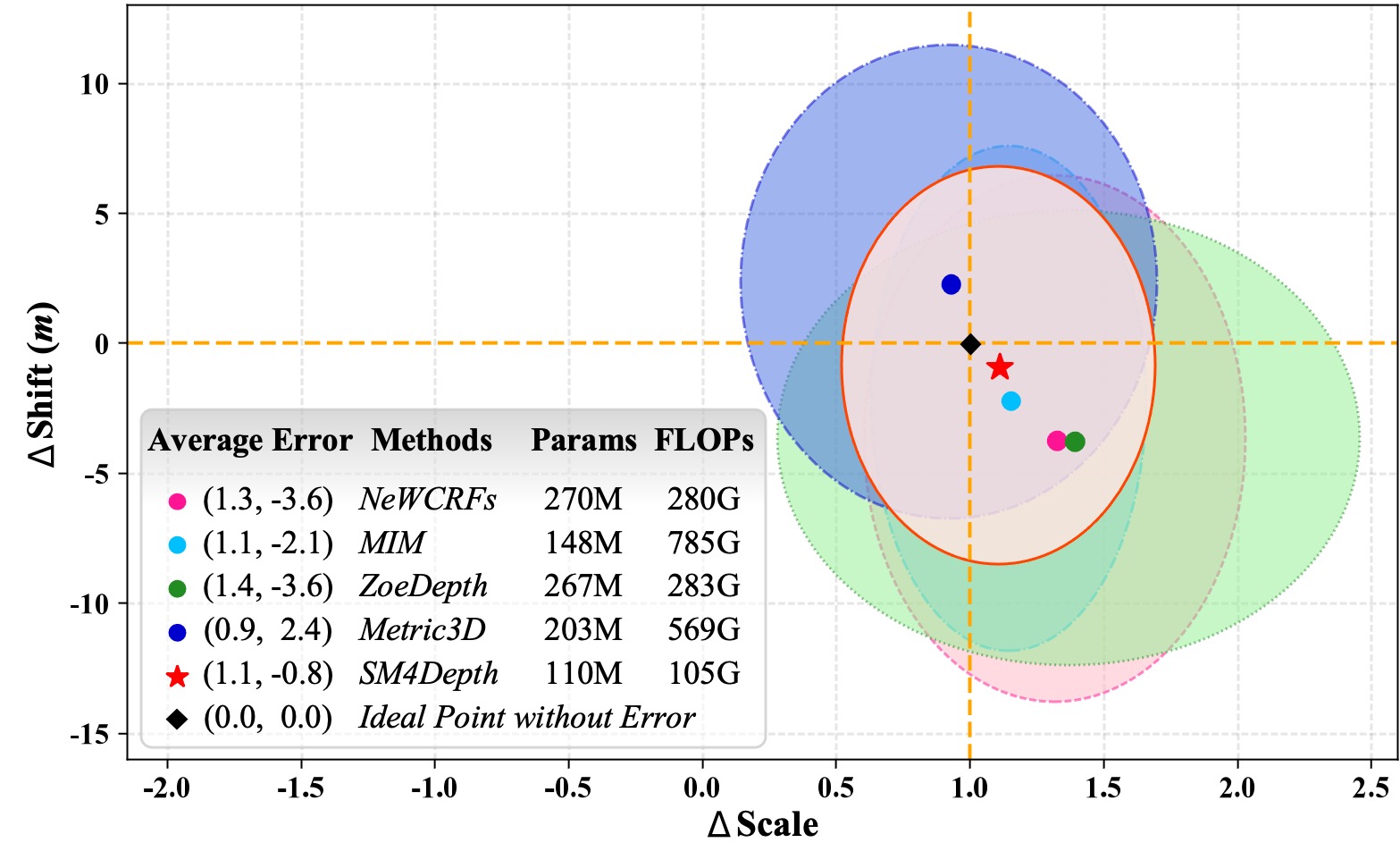
Lower Error in Scale and Shift
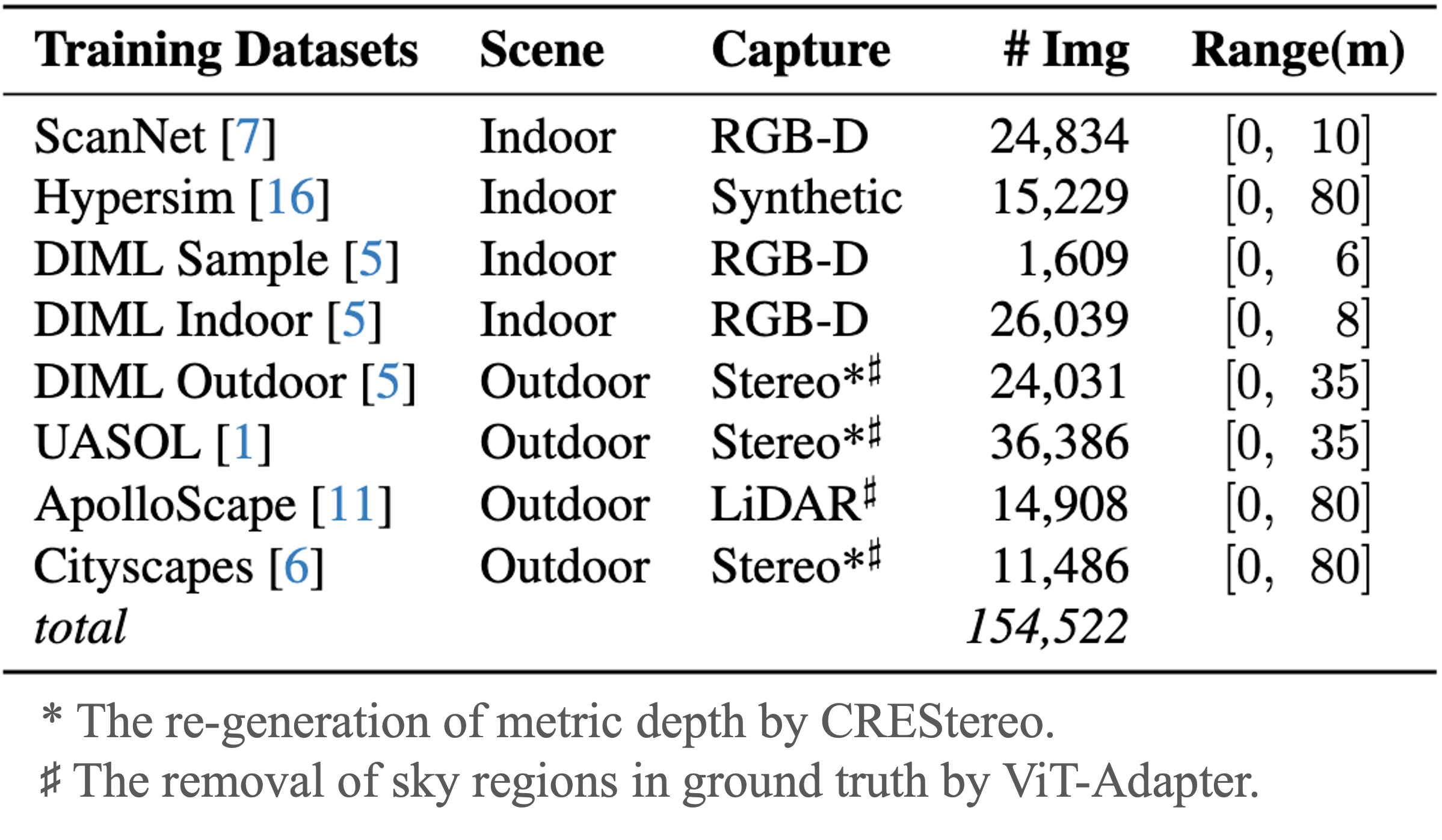
0.15M vs 800M Training Pairs
Consistent Results in indoors/outdoors
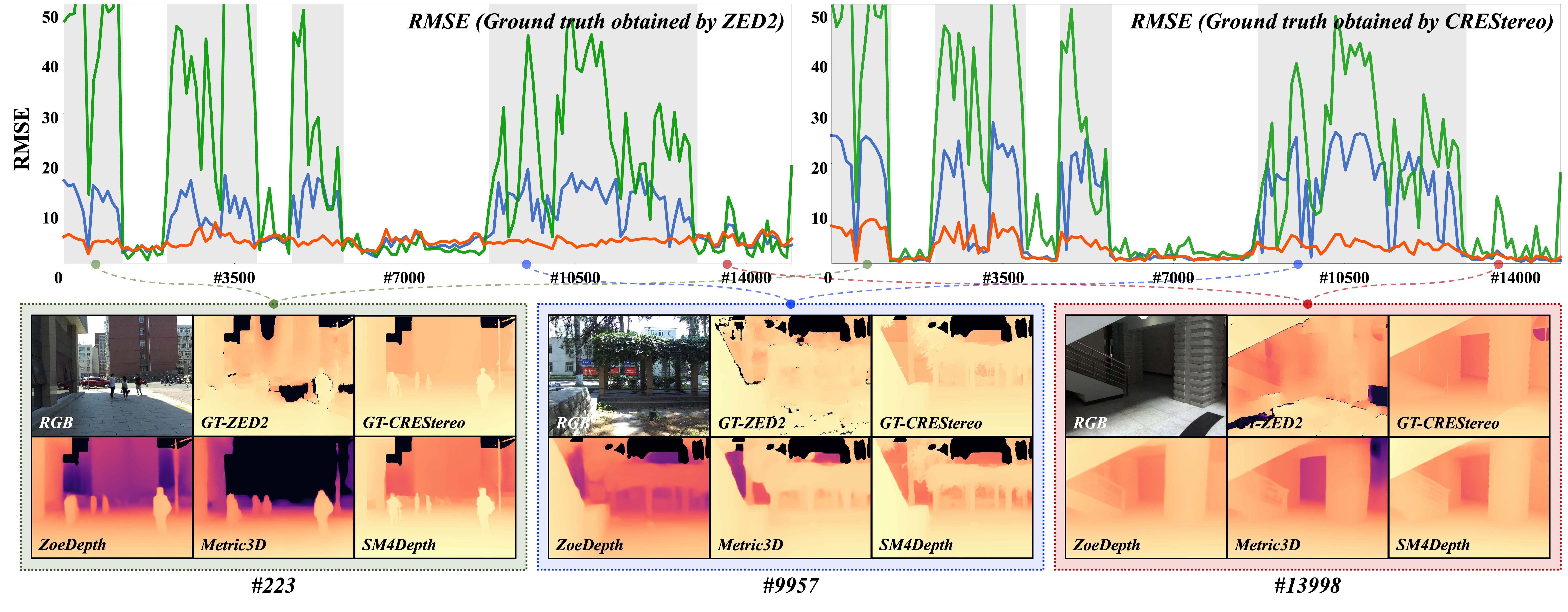
Real-world scenes vary widely in depth, making models tend to focus on specific
scenes and causing inconsistent accuracy across scenes. Tthe previous works suffered from large accuracy
fluctuations and high average errors, while our method reduces the errors.
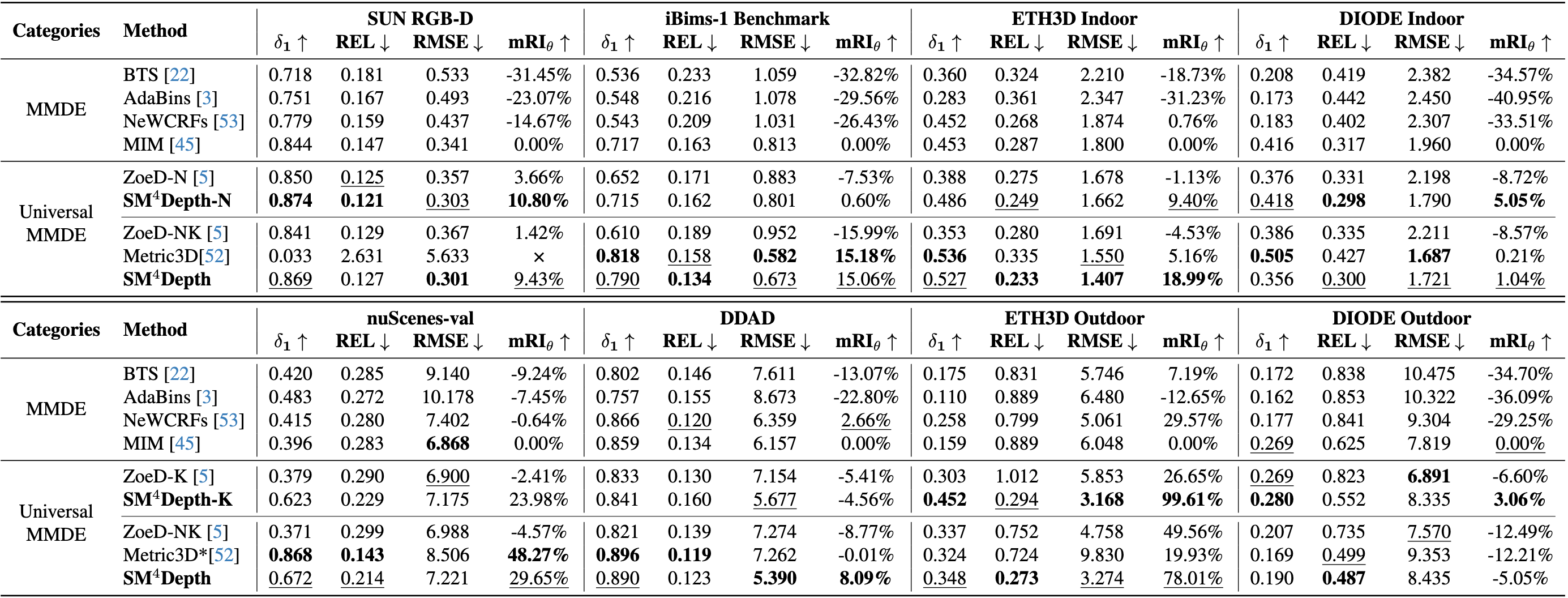
Compared to Metric3D, SM\(^4\)Depth performs better on most datasets, (i.e., SUN
RGB-D, ETH3D, DIODE, and DDAD) and similar on iBims-1, but is only trained 150K images, which proves
the effectiveness of SM\(^4\)Depth.
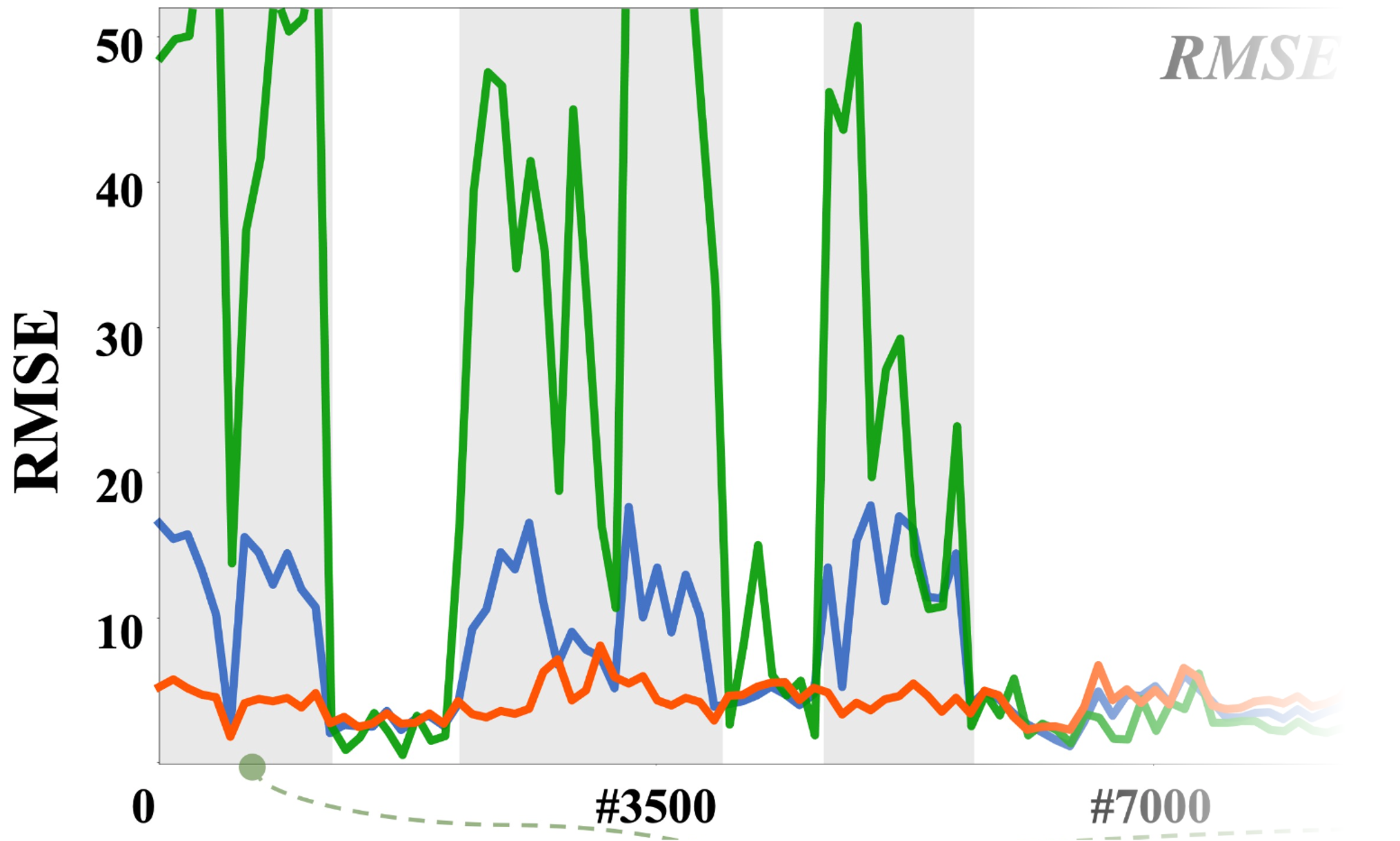
All the improvements are designed to ensure that SM\(^4\)Depth can obtain stable
metric scales in multi-scene seamless videos. The results show that SM\(^4\)Depth can achieve consistent
metric depth accuracy across both indoor and outdoor scenes.
Abstract
The generalization of monocular metric depth estimation (MMDE) has been a longstanding challenge. Recent methods
made progress by combining relative and metric depth or aligning input image focal length. However, they are
still beset by the challenges in camera, scene, and data levels: (1) Sensitivity to different cameras; (2)
Inconsistent accuracy across scenes; (3) Reliance on massive training data. This paper proposes SM\(^4\)Depth, a
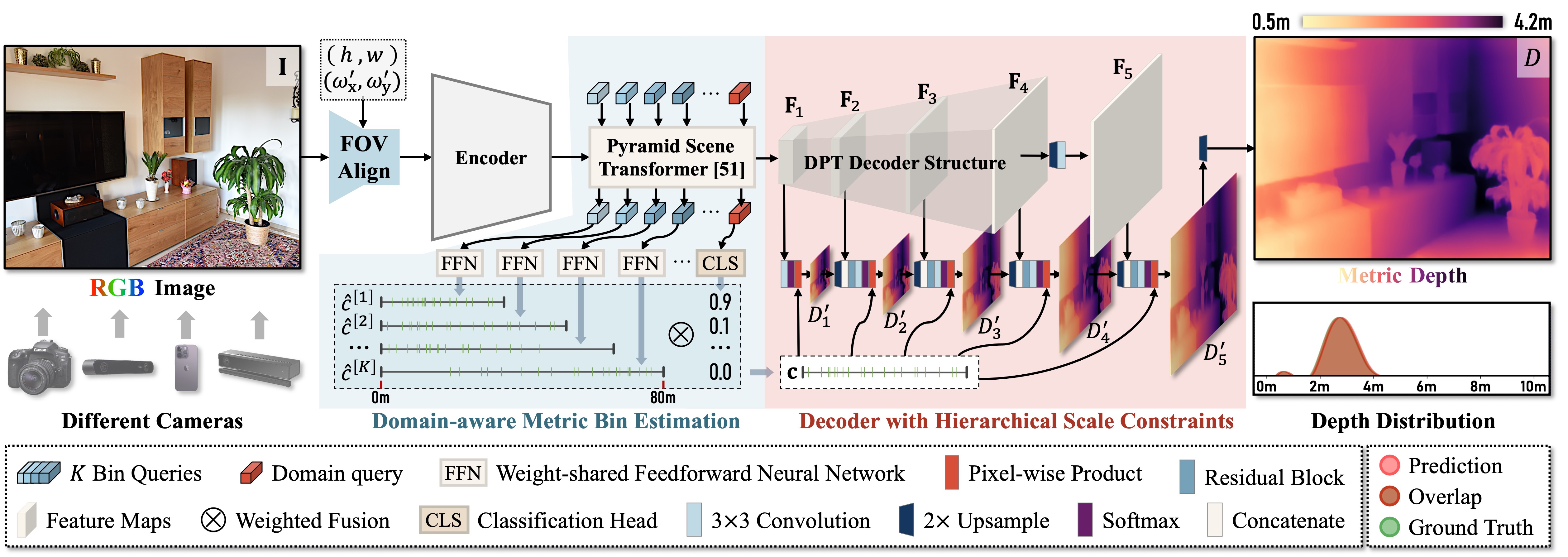
seamless MMDE method, to address all the issues above within a single network. First, we reveal that a
consistent field of view (FOV) is the key to resolve "metric ambiguity" across cameras, which guides
us to propose a more straightforward preprocessing unit. Second, to achieve consistently high accuracy across
scenes, we explicitly model the metric scale determination as discretizing the depth interval into bins
and propose
variation-based unnormalized depth bins. This method bridges the depth gap of diverse scenes by reducing the
ambiguity of the conventional metric bin. Third, to reduce the reliance on massive training data, we
propose a "divide and conquer" solution. Instead of estimating directly from the vast solution space, the
correct metric bins are estimated from multiple solution sub-spaces for complexity reduction. Finally, with just
150K RGB-D pairs and a consumer-grade GPU for training, SM\(^4\)Depth achieves state-of-the-art performance on
most previously unseen datasets, especially surpassing ZoeDepth and Metric3D on mRI\(_\theta\).
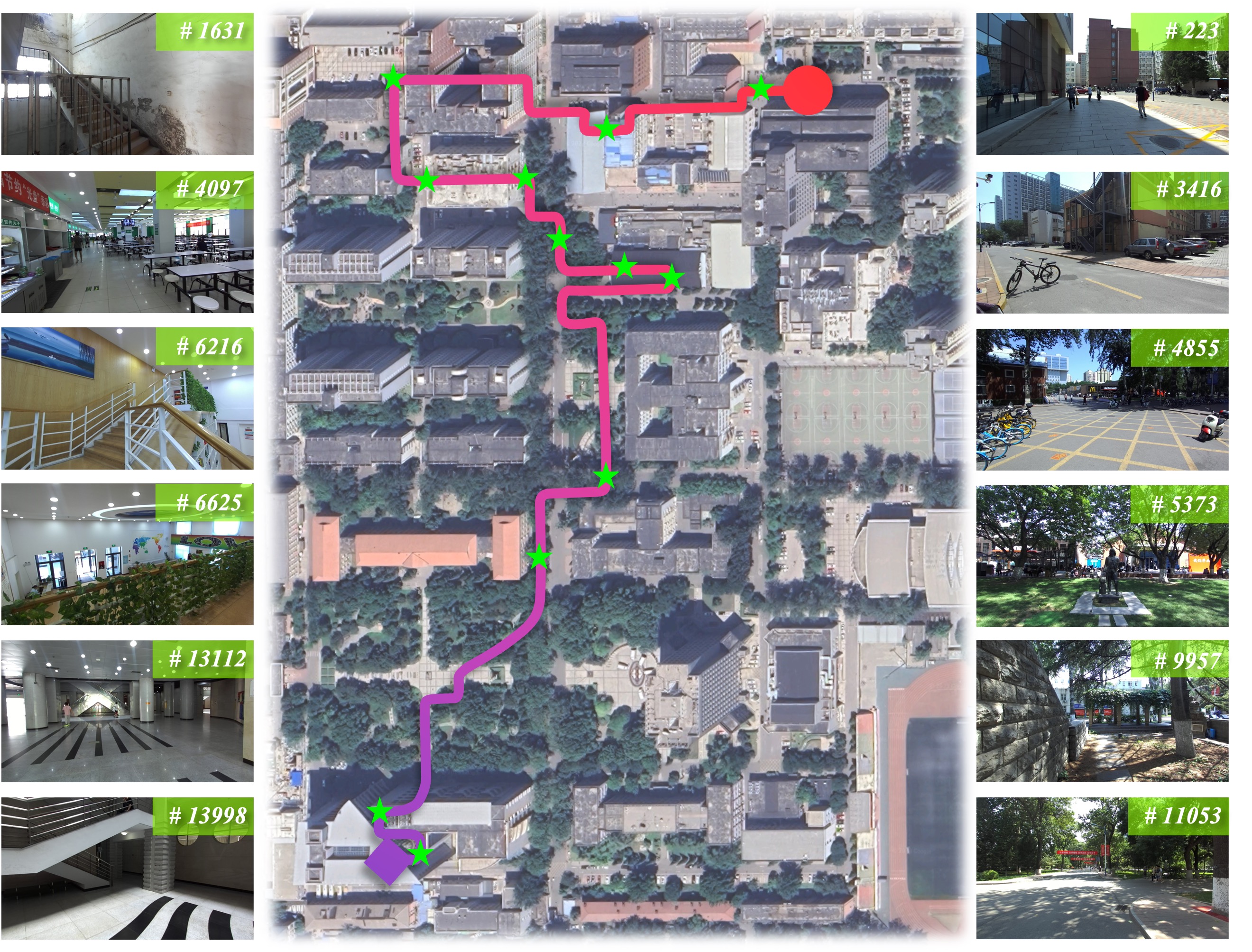
The BUPT Depth dataset is proposed to evaluate the consistency in accuracy across
indoor and outdoor scenes, including streets , restaurants, classroom, lounges, etc.
It consists of 14,932 continuous RGB-D pairs captured on the campus of Beijing University of Posts and
Telecommunications (BUPT) by a ZED2 stereo camera.
In addition, we provide the re-generated depth maps from CREStereo and the sky segmentations from ViT-Adapter.
The color and depth streams are captured with intrinsics of \(1091.517\) and a baseline of \(120.034 mm\).
Zero-shot seamless results for BUPT Depth dataset
Our method is marked in red, ZoeDepth in blue, and Metric3D in green.
Framework
BibTeX
@inproceedings{liu2024sm4depth,
author = {Liu, Yihao and Xue, Feng and Ming, Anlong and Zhao, Mingshuai and Ma, Huadong and Sebe, Nicu},
title = {SM4Depth: Seamless Monocular Metric Depth Estimation across Multiple Cameras and Scenes by One Model},
booktitle = {Proceedings of the 32nd ACM International Conference on Multimedia (MM '24)},
year = {2024},
publisher = {ACM}
}